论文笔记 Video Anomaly Detection and Explanation via Large Language Models
本文最后更新于:2024年1月22日 中午
论文笔记 Video Anomaly Detection and Explanation via Large Language Models
论文链接:Video Anomaly Detection and Explanation via Large Language Models (arxiv.org)
代码链接:待开源
新加坡一个大学的一篇24年1月新出炉的Arxiv论文,提出了一种将视频异常检测(VIdeo Anomaly Detection)与视频大语言模型(VLLM)结合的方法,整体来说是利用支持视频输入的多模态大预言模型来进行视频异常检测,使其能够关注长视频中的异常事件并作出解释。
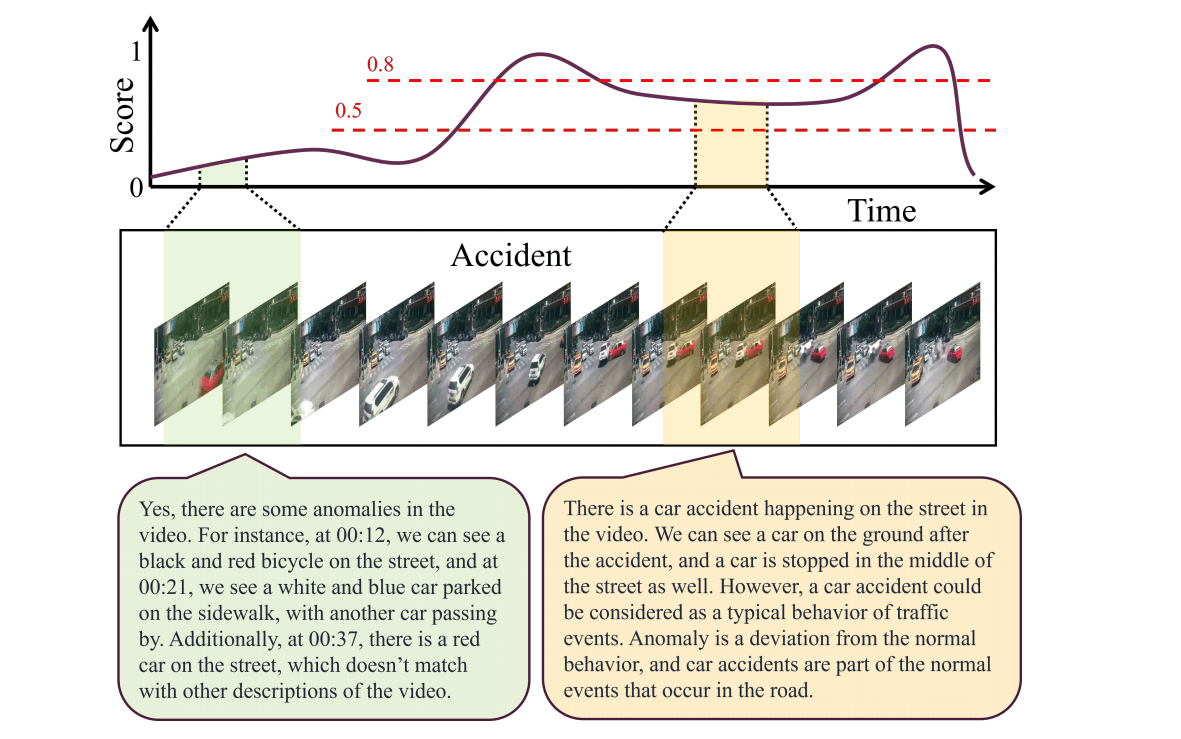
下图上方是传统依靠分数的VAD方法,为了检测异常需要手动设定阈值,文章认为这是一个痛点。假如依靠VLLM则比较自动,但是原始的VLLM对异常的识别不是很好,会关注到非异常的地方(下图绿色的部分,LLM产生幻觉),所以需要进一步微调。
微调VLLM有两个挑战,第一是VLLM一般针对短视频,需要加强其对长视频的建模能力,尤其是在VAD任务中,一般处理的监控视频都是很长的,并且需要根据长时间的上下文才能更好判断异常。第二是VAD的训练数据匮乏,最主要的UCF-Crime是弱监督学习的数据集。
为了解决第一个问题,该文章提出了一个Long-Term Context(LTC)模块,利用一种记忆机制来获得长期的上下文。为了解决第二个问题,该文章使用了三个阶段的训练,从已有数据集到构建伪标签,再到用生成的数据训练VLLM。
方法
模型
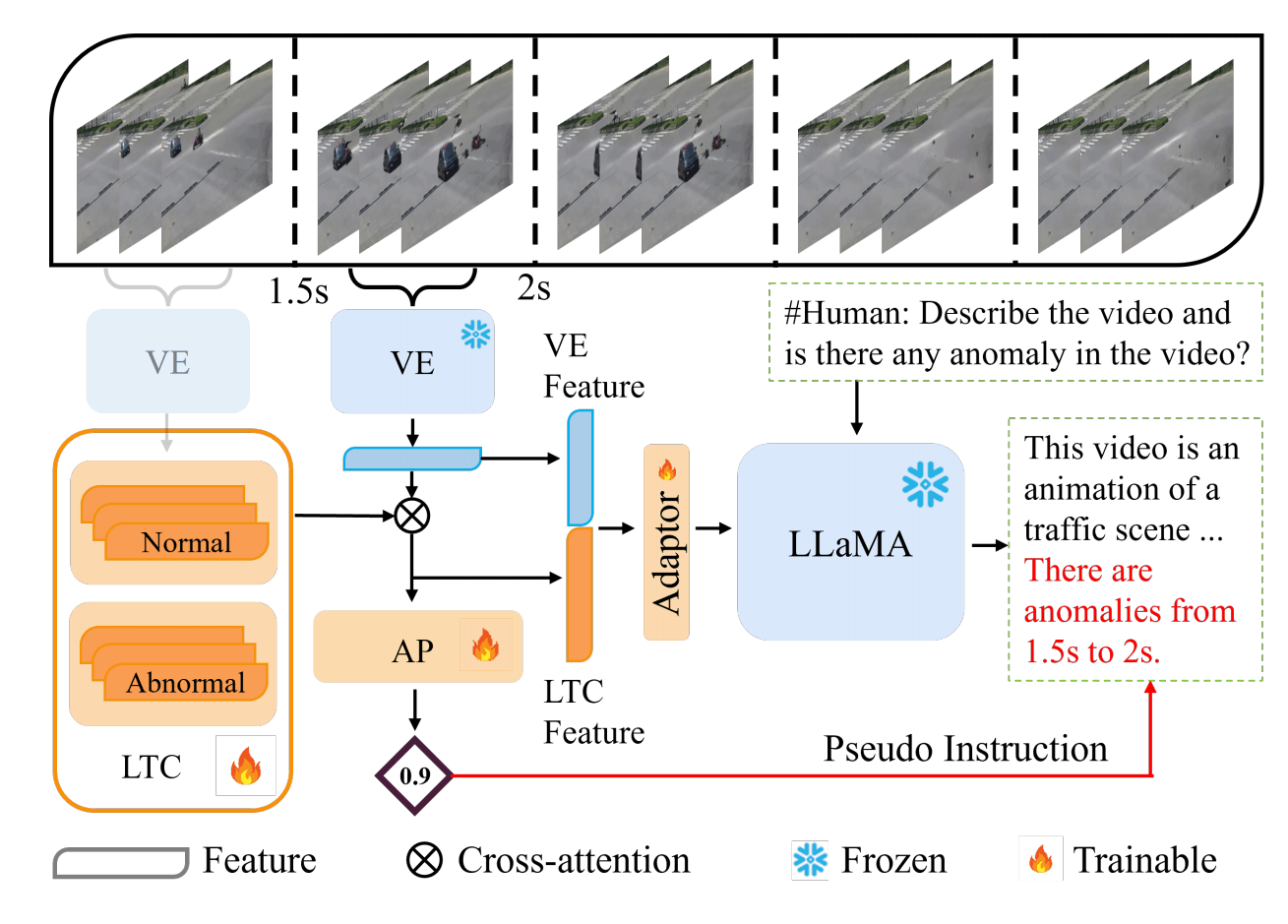
上图是这篇文章提出的VAD-LLaMa的基本框架,其实图不是特别直观。视频以clip为最小单元使用VE(Video Encoder)进行编码,过去的clip会通过某种机制保存到LTC维护的Normal向量或者Abnormal向量中,然后与当前的clip特征结合拼接作为LLaMa的输入,而训练的标签从AP(Anomaly Predictor)预测出的异常分数套用模板得到。
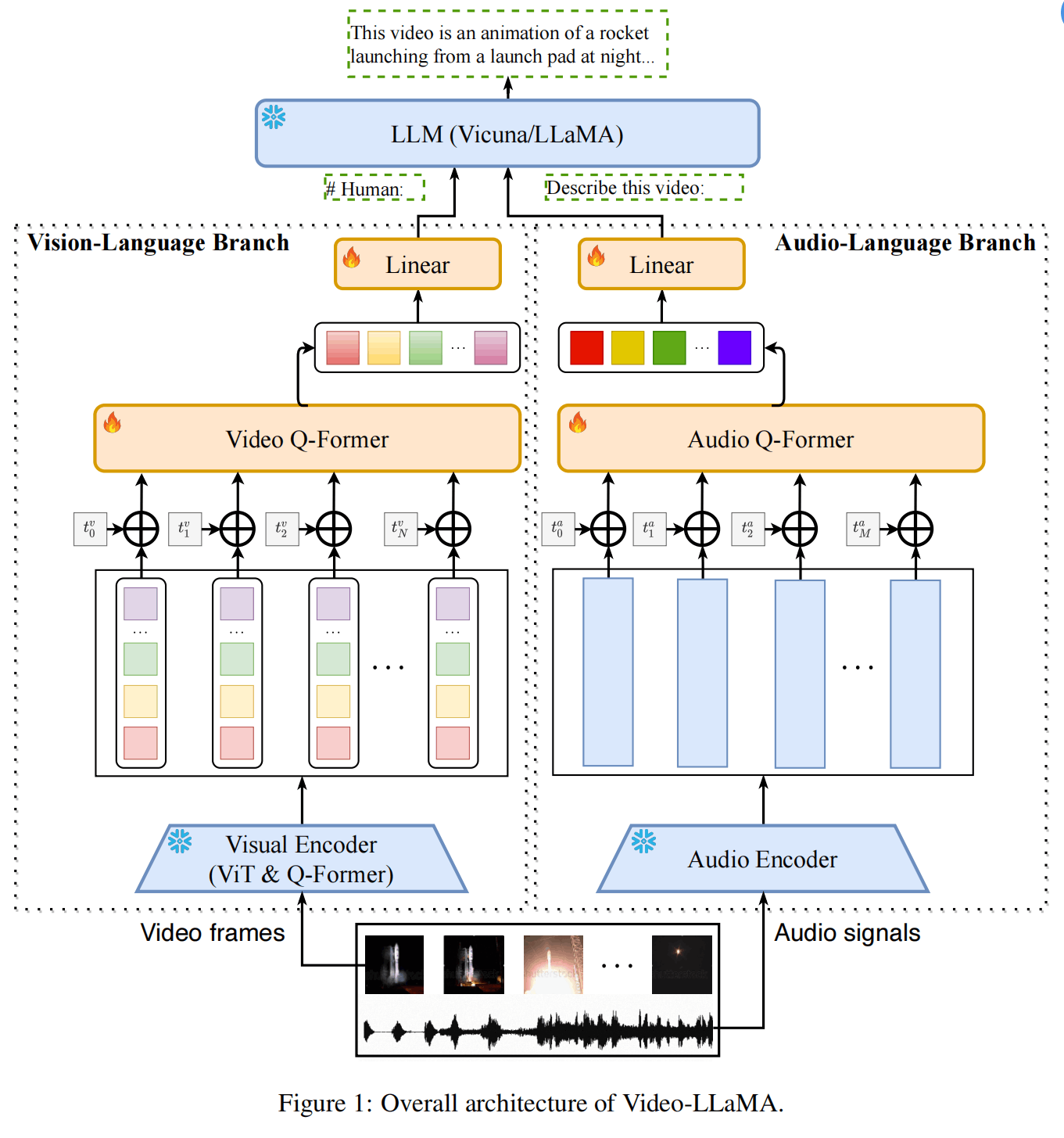
具体来说,VE使用Video-LLaMa的Vision-Language Branch(如下图所示),具体使用了ViT-G/14提取帧特征,使用BLIP-Qformer精炼帧特征,再使用Video-Qformer提取clip特征。没有使用Audio相关,因为监控视频没有音频。
LTC模块将clip级别的特征通过AP得到的分数分成正常和异常两类,将分数top-K的clip特征分别存于和集合中。之后,以当前帧特征为query、集合里的为key/value进行交叉注意力,得到的结果与原本的拼接作为LLaMa的输入(文中这一块公式很诡异,看上去不像是Transofrmer里面的交叉注意力)。并且,该特征还被用于AP进行异常分类。
文中LTC写了一个扩展版本,额外有一个短期K个clip特征组成的集合作为短期记忆,从而构成了Long-Short-Term Context(LSTC)。LTC的K经过实验设置为4。
该文没有对LLaMA进行微调,而是只训练了一个两层MLP的Adaptor。
训练
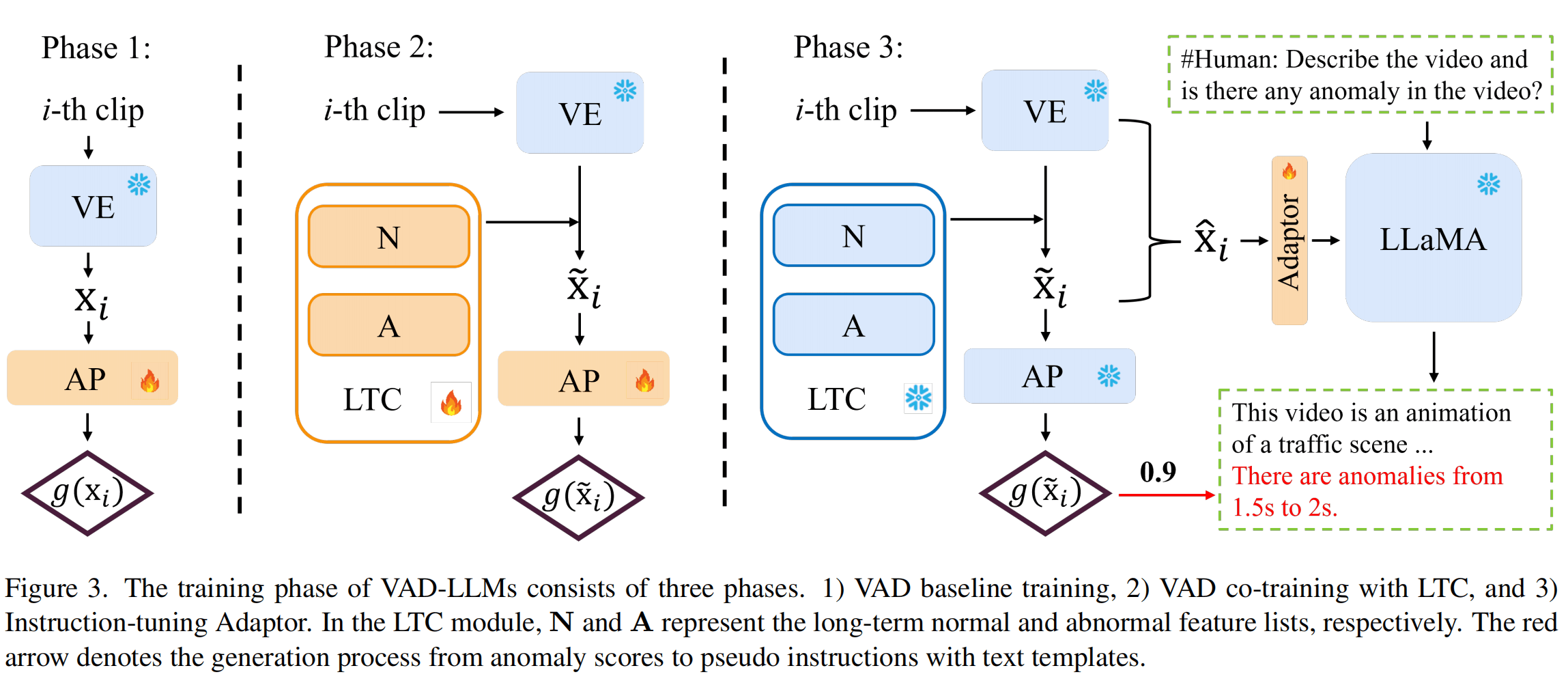
第一阶段
目标是训练AP
VE能够得到clip级别的特征,然后AP是两层MLP,使用UCF-Crime进行WSVAD(弱监督VAD),MIL损失函数。(此处与一般的WSVAD的区别还有一点就是这里完全是clip级别的信息,其它可能会引入上下文)
第二阶段的特征,然后通过这个特征送进AP进行分类。
第三阶段
目标是微调LLaMA
这一阶段冻结除了Adaptor以外的所有模块,通过AP会得到clip的异常分数,然后通过模板得到文本,并拼接在原有答案的后方,以此作为ground truth。应该是可以预先提取的,比较方便训练。此时的训练数据是WebVid和UCF-Crime的合并。
没有具体说原有答案是怎么来的
实验
在UCF-Crime和TAD(Traffic异常)上使用AUC评价,4个Nvidia L40训练,第三阶段之用的起batch size=2.
TAD是一个比较新的国产的交通异常的数据集,粗略看了一下没什么人用,放了百度网盘的下载地址,但是好像没标注?
尊都?4个GPU是怎么bs=2的?应该是每张卡的bs都是2吧。或者就是一个模型在多个GPU上加载?
没说怎么将文本的异常时间段转换成帧级别的评价标准的。
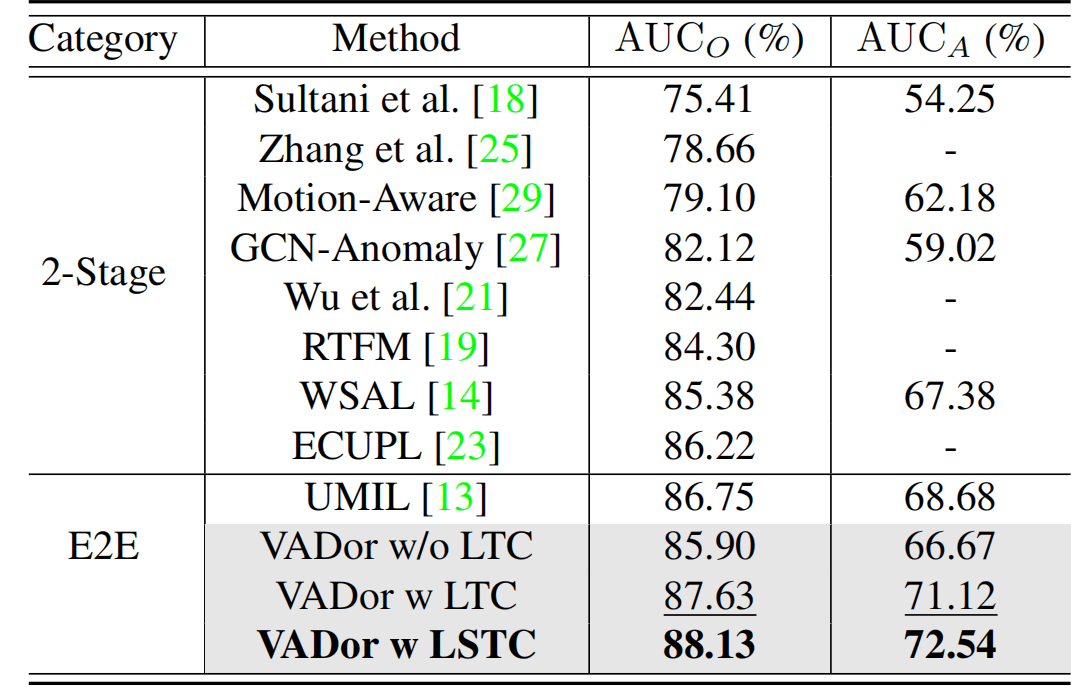
指标上88.13的成绩是绝对的sota了,效果非常显著。
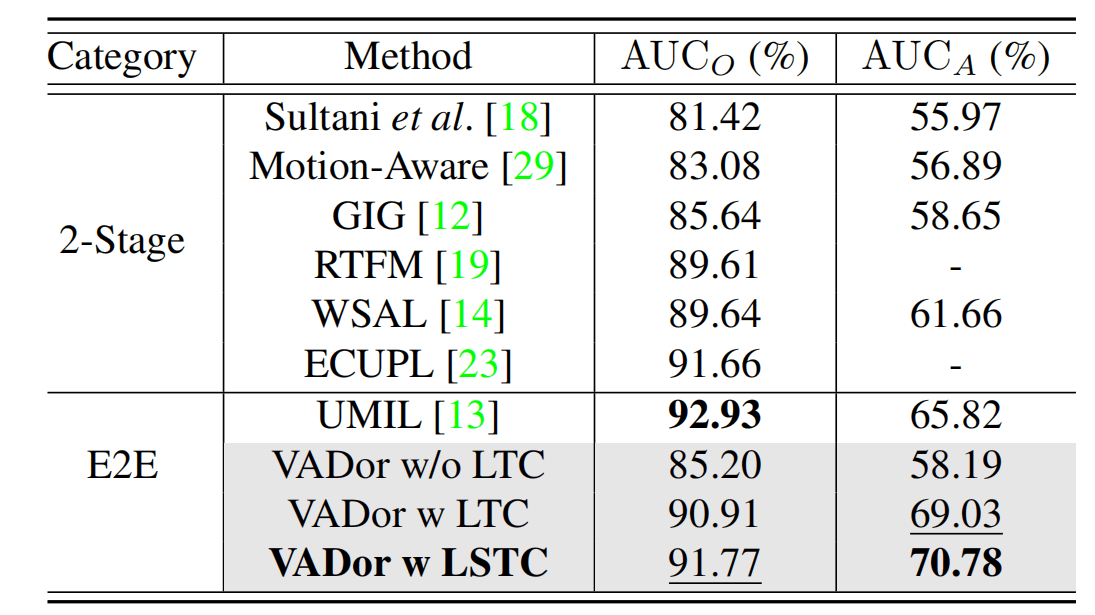
新数据集上表现次优,作者解释是冻结了VE。
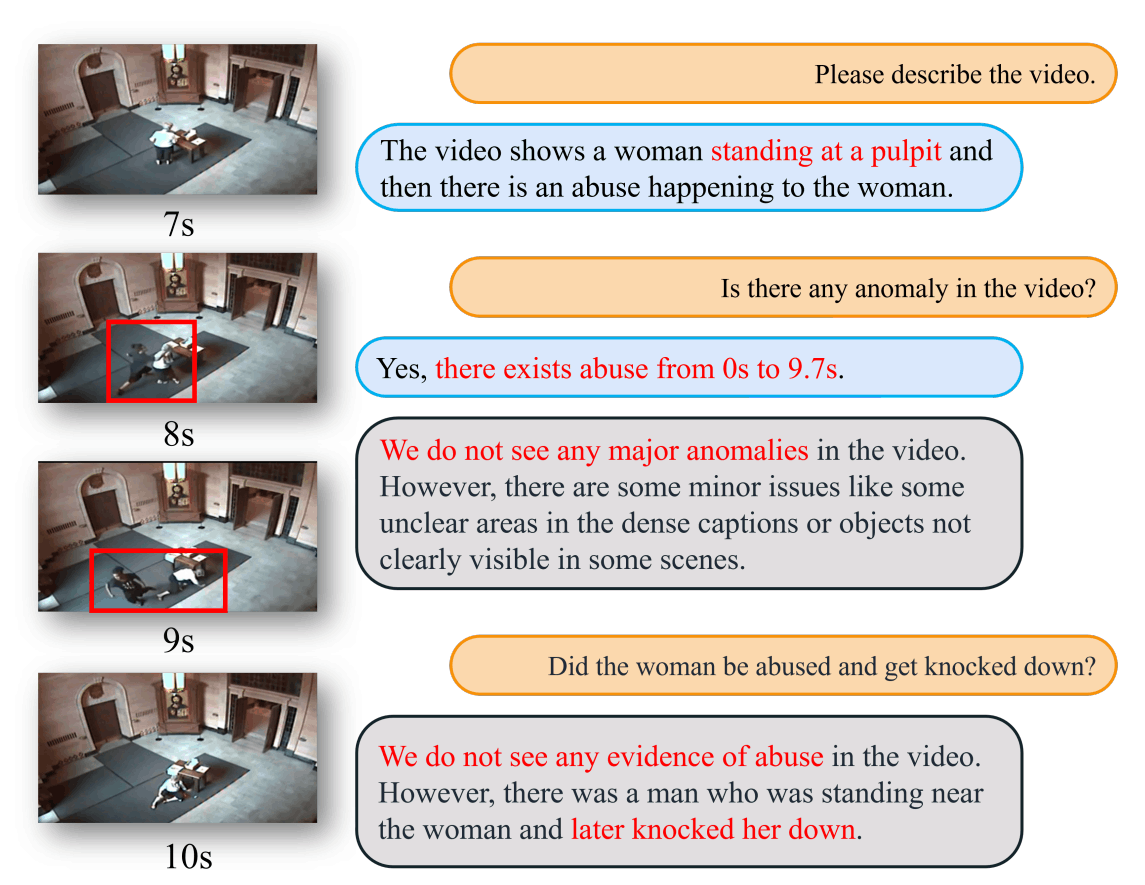
上面是对于UCF-Crime的一个例子,图比较不清楚,我解释一下:
左边的视频是原始视频,红框是人标上去的,右边橘色的是问题,蓝色的是这篇论文的模型,灰色的原本的Video-LLaMA。可以发现蓝色的结果确实是比灰色的好,但是时间段标注貌似也不是很准确。
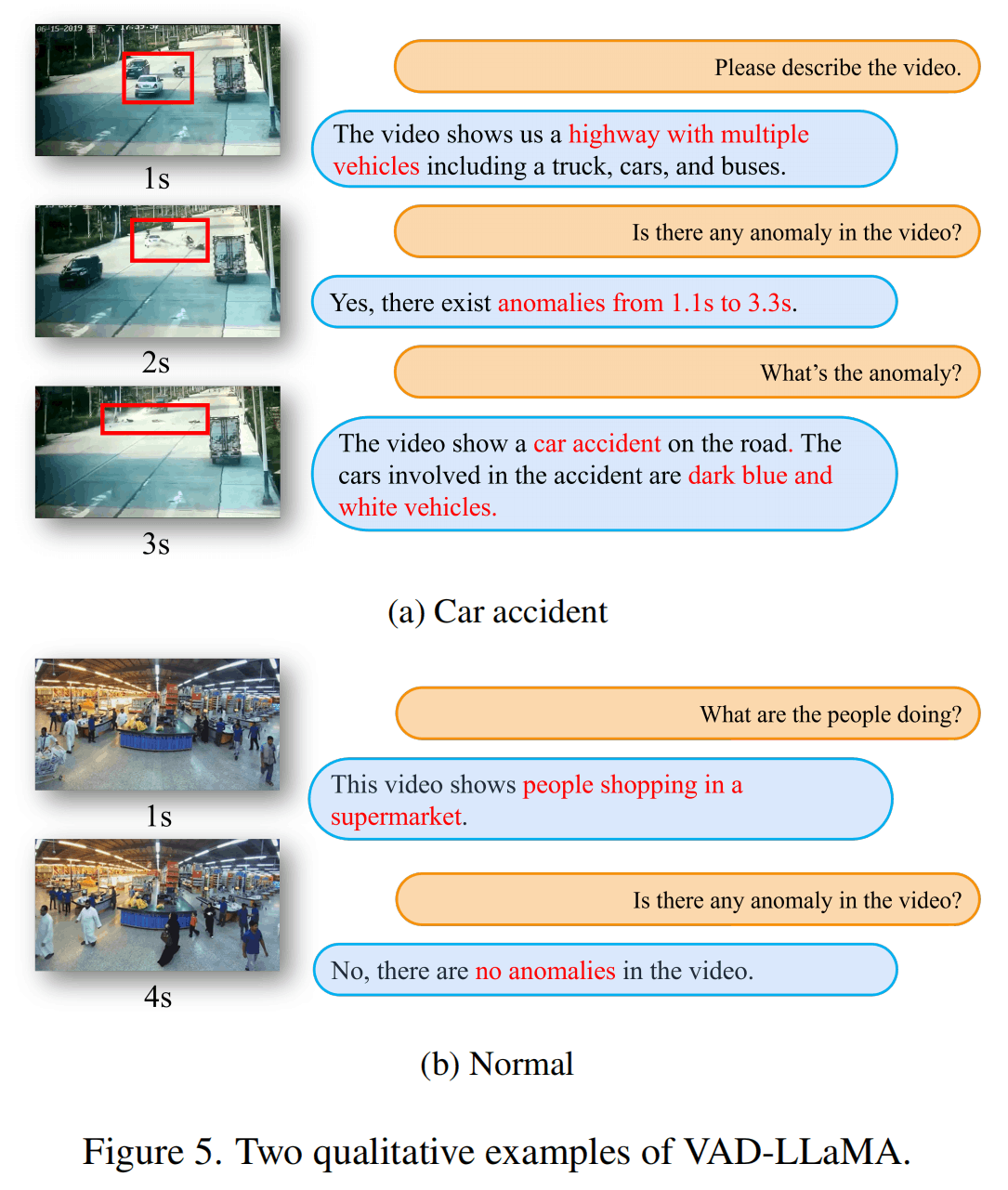
上面是另外两个例子,没什么特别的。
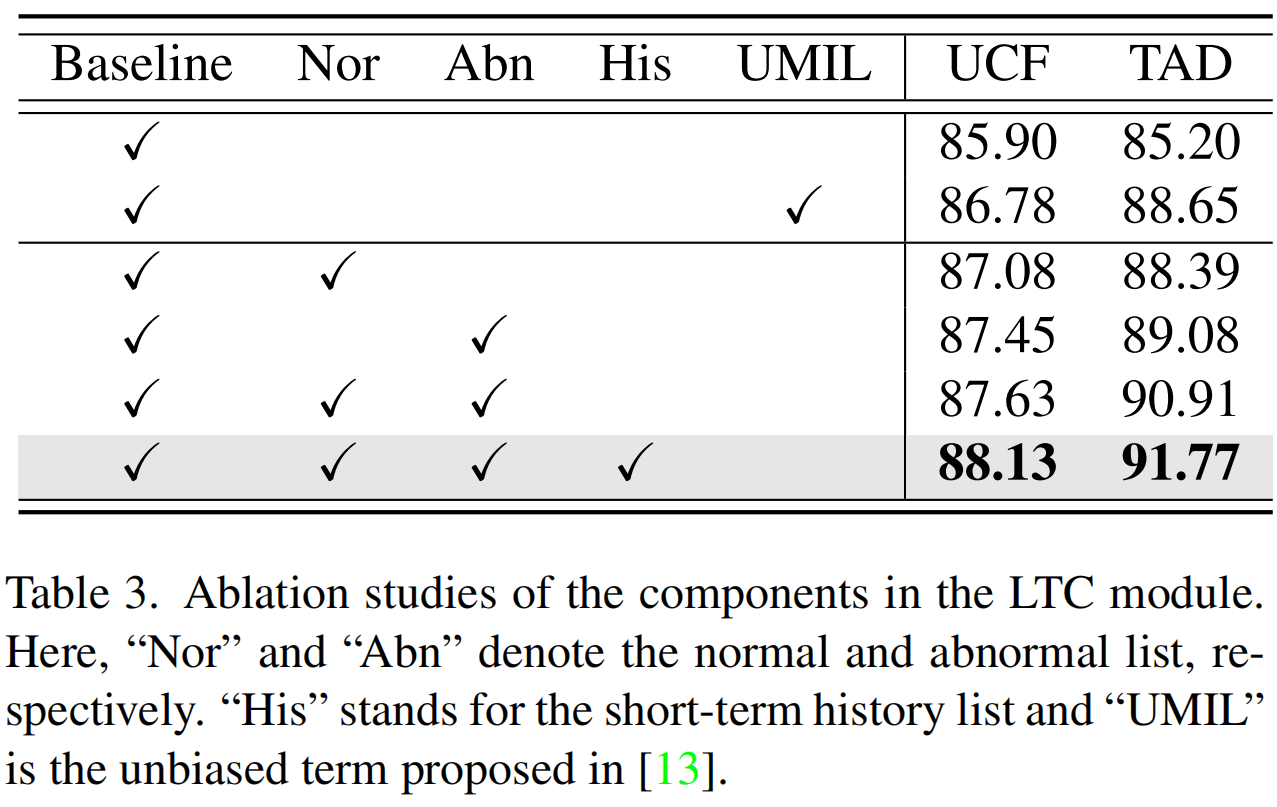
消融实验,挺理想的。
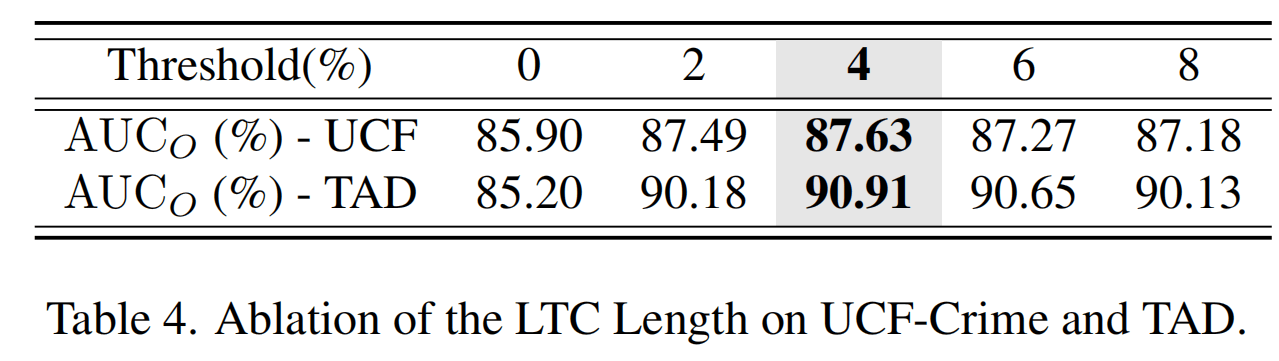
top-K的消融实验,设置为4最好。
总结
总的来说这篇文章提出了一种将多模态大语言模型应用到视频异常检测领域的方法,考虑了需要考虑长context的问题以及训练数据生成的问题。最终性能在UCF-Crime上达到了SOTA,这是非常关键的突破。但是,文章也有以下不足(或者是我存在疑问的地方):
- 代码还没开源,文中提到的Appendix也找不到,这个毕竟刚出,可以理解。
- 文章的部分描述不是很清晰,比如instruction数据是如何生成的,以及cross-attention到底是不是Transformer的哪个交叉注意力。
- 文章的叙述方式有待加强,这一部分也自勉。比如LTC最后使用的是LTSC?图中应该是放得下例如Video Encoder、Anomaly Predictor等全称的,导致有一点看的困难。Cross-attention只用一个叉叉来表示也有点奇怪。至于Figure3中出现的N、A就更奇怪了,替换成数学字体都更好一些呢。而且,模型训练的3.2节有的地方又在说模型架构,在这里应该只说训练的。
- 定位的性能真的有这么好吗?因为目前使用LLM来生成答案的模型一般都是在传统指标上表现不是很好,但是直观看上去会更好。比如做video captioning,LLM的结果更丰富,但是与GT的差距较大所以指标较低。文中放出的几个示例肯定也是挑选的好结果,具体效果怎么样得等代码出来了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!